Posts
2020-02-17
Pearson OnVUE Broke Mac Mission Control
Pearson OnVUE Broke Mac Mission Control Pearson has started offering Online Proctored exams. You download the OnVUE application and take the exam from the comfort of your home. This sounds great, but …
Posts
2020-01-08
Cloud Storage and Trailing Slashes
Cloud Storage and Trailing Slashes Shortly after configuring this site to be served simultaneously from AWS, Azure and GCP, I realize I had a bug. Occasionaly the images were not loading. Ironically …
Posts
2019-12-30
Multi-Cloud Blogging
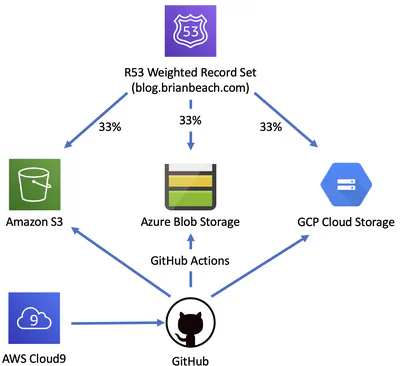
I spent some time over Thanksgiving moving my blog from Blogger to Hugo. I have been hosting my site in an Amazon S3 bucket with an automated build in AWS CodeBuild. That has been running well for the …
Posts
2019-12-11
Hugo Robots Meta Tag
When I first moved over to Hugo, I struggled to get the robots meta tag working. Note that I am using the Ananke theme and this may be different for other themes.
Primer Honestly, I have not spent a …
Posts
2019-11-29
Running Hugo Server in AWS Cloud9 Preview
I have been moving my blog to Hugo over the holiday weekend. I am working in a Cloud9 instance. Cloud9 allows you to preview an application running in the Cloud9 instance by proxying the connection …
Posts
2019-07-23
DNS Resolution for Private EKS Cluster
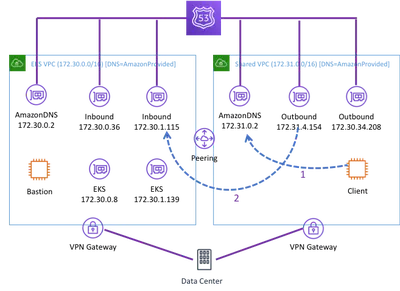
I have been working on a project to deploy Elastic Kubernetes Service (EKS) at an Academic Medical Center. They want to deploy a private cluster that does not have internet acess. EKS supports this, …
Posts
2018-04-04
Writing unit tests for Chalice
Chalice is a Python serverless microframework for AWS that enables you to quickly create and deploy applications that use Amazon API Gateway and AWS Lambda. In this blog post, I discuss how to create …
Posts
2017-04-08
Elastic Beanstalk Worker Environment Timeouts
I have been working with Worker Environments in AWS Elastic Beanstalk. I found all the timeouts confusing at first, so I share my findings here.
The instances in your Worker Environment have a demon …
Posts
2017-03-17
EBS Snapshots with Microsoft VSS and EC2 Systems Manager.
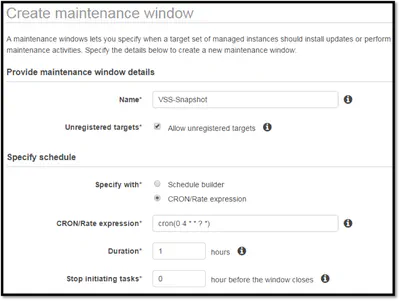
Early in my career, I learned an important lesson: backup is easy, but restore is hard. Too often we take our backup and recovery for granted. We assume that if the backup completed successful, the …
Posts
2016-11-10
Simple Email Service (SES) Sample Application
I could not find a simple example to send email using SES in Python. Turns out it is really easy. If you have a MIME formatted message you can simply call send_raw_message.
1 2 client = …
Posts
2016-11-06
Linked Account Template
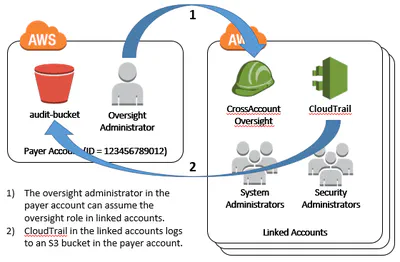
It is common for an AWS customer to have many accounts. Often a central IT team will own the payer account and have oversight over all accounts. The IT team will create a linked account for …
Posts
2016-10-08
CloudWatch Logs Trace Listener
I added a new Cloud Watch Logs Trace Listener to the .Net API for AWS. The API team plans to add support for Log4Net, but in the meantime I have been using this. …
Posts
2015-10-04
My Cloud EX2 Backup to Amazon S3
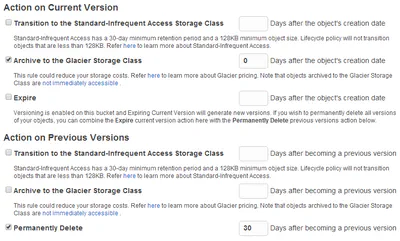
With all the devices in the house it was finally time to invest in a NAS. I settled on the Western Digital My Cloud EX2. I picked this specifically because it supported back up to Amazon S3. In …
Posts
2015-04-15
Configuring an AWS Customer Gateway Behind a NAT

I have been wanting to configure a VPN Connection from AWS to my house, but my cheap Netgear router does not support IPSec. So, I picked up an old Cisco 871 router that does. I didn’t want to …
Posts
2015-02-06
Discovering Windows Version on EC2 Instances
Windows Server 2003 end of life is less than six months away. As I start to think about upgrading, I was looking for an easy way to identify what version of Windows is running on each EC2 instance. …
Posts
2014-12-14
Configuring a Linux Swap Device with Cloud-Init
Cloud-Init is a set of Python scripts used to configure Linux instances when they boot in AWS. Cloud-Init is included on Ubuntu and Amazon Linux AMIs.
You can think of a Cloud Init script as a …
Posts
2014-09-30
CloudWatch Logs Push
In my last post I used the awslogs daemon to push tcpdump events to AWS CloudWatch logs. At the time it felt silly to use a file on disk and a daemon to push events from an interactive session. …
Posts
2014-09-26
CloudWatch Logs and TCPDump
I was recently debugging an issue with a fleet of Apache web servers. I needed to watch for some low level network events we felt might be causing an issue (TCP resets, etc.). I thought …
Posts
2014-08-10
Decoding Your AWS Bill (Part 3) Loading a Data Warehouse
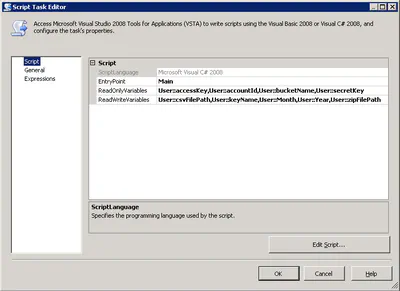
In the last two posts (part 1, part 2) in this series we used PowerShell to gleam information from our monthly AWS billing report. While you can use those scripts to learn a great amount of …
Posts
2014-08-09
Decoding Your AWS Bill (Part 2) Chargeback with Tags
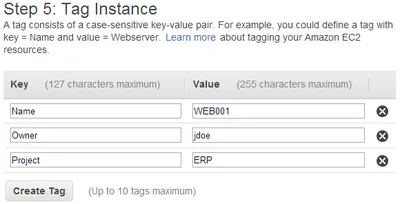
It took 6 months but I finally got time to continue the series on Decoding Your AWS bill. In the last post, we used PowerShell to download and query the monthly bill. In this post we use …
Posts
2014-07-16
Bulk Importing EC2 Instances
I have been testing a a preview of a new PowerShell command, Import-EC2Instance, that will be added to the AWS PowerShell API next week. The new command allows you to import a VM from VMware or …
Posts
2014-06-20
Writing to the EC2 Console
I have been building a bunch of Windows AMIs for EC2 recently. If the instance fails to build it can be a real bear to diagnose issues. You don't have access to the console to watch what's happening. …
Posts
2014-05-30
Setting the Hostname in a SysPreped AMI
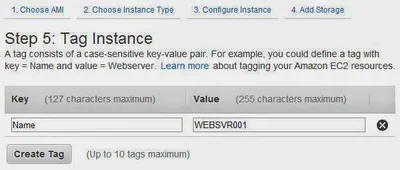
When you create an Windows AMI (Amazon Machine Image) it is configured to generate a random server name. Often this name does not meet your needs. Maybe your company has a specific naming convention …
Posts
2014-01-25
Decoding Your AWS Bill (Part 1)
As you begin to adopt AWS you will likely be asked to report on both usage and cost. One way to do this is using the Monthly Billing report. In this post I will show you how to download your bill and …